RaspberryPiで家の騒音をグラフ化
赤ちゃんがいつ泣いているのかログを取りたい
 1日何時間泣いているのかや、
1日何時間泣いているのかや、
何時頃に泣くなど傾向がわかったら面白そうなのでやってみました。
用意するもの
- RaspberryPi 2 or 3
- USBマイク
環境準備
Elasticsearch×kibana×Fluentdのインストール
グラフ化するために以下環境を用意します
Python3のインストール
Pythonは2系と3系がありますが、今後主流になっていく3系を使います。
普通はpyenvやvenvを挟んで環境を切り替えることが多いですが、
RaspberryPi上だとうまくできなかったので、
シンプルに直接Python3系とモジュールをインストールします。
$ sudo apt-get install python3 python3-numpy python3-pyaudioマイクデバイスの認識
こちらのサイトにマイクデバイスの設定方法が書いてあるので、参考にさせていただきました。
設定後以下のようにUSBデバイスが優先されていればOKだとおもいます
$ cat /proc/asound/modules
0 snd_usb_audio
1 snd_bcm2835マイクのサンプリング周波数を確認
マイクから信号を受け取りにあたりサンプリング周波数を設定する必要があります。
マイクに合った設定をしないとエラーが出て取得できません。
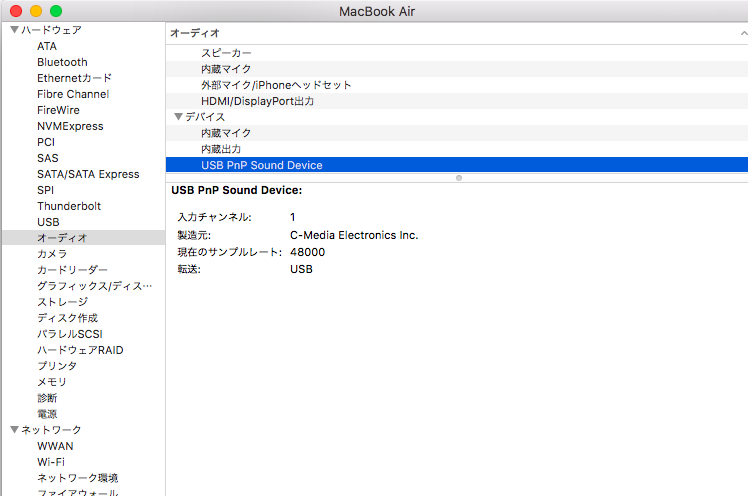
サンプリング周波数はUSBマイクを一度Macに挿して
システム情報->ハードウェア->オーディオ->デバイス
にUSB PnP Sound Deviceの欄で確認できました。
※Windowsの場合は試していませんがデバイスマネージャなどから確認できるかもしれません
騒音をログ化する
動作のながれ
- マイクからのストリーミングデータをCHUNK分(1024*2)ずつ抜き出してその中で最大振幅を配列max_dataに入れる。
- Thredingを使って指定時間ごとに割り込み処理(sendlog)を実行
- 割り込み処理では配列max_dataの平均値を計算してFluentdに送り、max_dataを初期化
Pythonでの割り込み処理はThredingモジュールで実装
Fluentdへはsubprocessでechoを使って実装
コード
# -*- coding:utf-8 -*-
import pyaudio
import numpy as np
import threading
import subprocess
max_data=[]
CHUNK=1024*2 # マイクによって変わる。上手くいかない場合色々試してください
RATE=48000 # 事前に確認したサンプリング周波数
p=pyaudio.PyAudio()
stream=p.open(format = pyaudio.paInt16,
channels = 1,
rate = RATE,
frames_per_buffer = CHUNK,
input = True,
output = True)
def audio_trans(input):
frames=(np.frombuffer(input,dtype="int16"))
max_data.append(max(frames))
return
def sendlog(): # 定期的に呼び出される
global max_data
if len(max_data) != 0: # 初回実行時だけ無視
mic_ave=int(sum(max_data)/len(max_data)) # 60秒間のマイク受信音量の平均値を出す
max_data=[]
#print("スレッドの数: " + str(threading.activeCount())+threading.currentThread().getName()) #Thredingでプロセスが乱立しないかチェック用
## fluentdに最大音量値を渡す
json = '{'+'\"mic_max\":{0}'.format(mic_ave)+'}'
cmd = "echo '" + json + "' | /usr/local/bin/fluent-cat log.hoge"
try:
print (cmd)
res = subprocess.check_call(cmd, shell=True )
except:
print ("error")
t=threading.Timer(60,sendlog) #60秒ごとにsendlogを実行
t.start()
t=threading.Thread(target=sendlog)
t.start()
print ("mic on")
while stream.is_active():
input = stream.read(CHUNK)
input = audio_trans(input)
stream.stop_stream()
stream.close()
p.terminate()
print ("Stop Streaming")実行結果
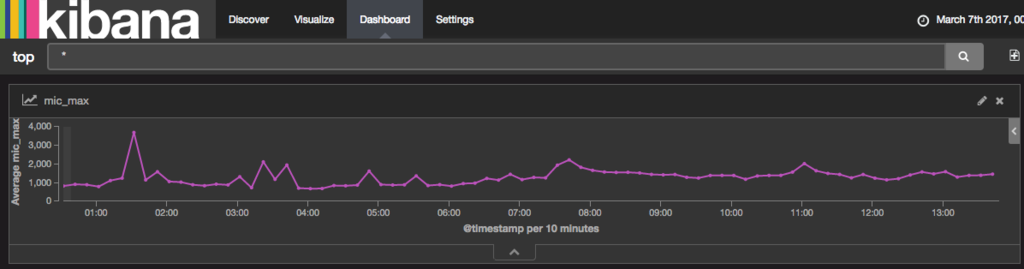
1、2時間ごと夜泣きをしてそのタイミングでグラフが上昇。
朝方を過ぎた頃に子供を移動させたのとテレビをつけたので全体的に平坦になっているわかる。
感想
マイクの受信感度やメモリ管理などまだまだ調整する箇所はありますが、
やりたいことはできた感じ。
マイクはベビーベッドに設置してましたが、
泣いたタイミングで抱っこして違う部屋であやしたりしていたので、
数値の大きさはあまり当てにならない結果になってしまいました。
※上昇タイミングだけ意味のあるデータとなった
参考サイト
http://karaage.hatenadiary.jp/entry/2015/08/24/073000
http://takeshid.hatenadiary.jp/entry/2016/01/10/153503
http://ja.stackoverflow.com/questions/24508/python%E3%81%AEthreading-timer%E3%81%A7%E5%AE%9A%E6%9C%9F%E7%9A%84%E3%81%AB%E5%87%A6%E7%90%86%E3%82%92%E5%91%BC%E3%81%B3%E5%87%BA%E3%81%99%E3%82%B5%E3%83%B3%E3%83%97%E3%83%AB